
تغییرات هستههای جدید کورتکس ARM را میتوان به دو بخش «استفاده از معماری جدید و بهبودهای کلی» و«ریزمعماری جدید هستههای A75 و A55» تقسیم کرد. در قسمت قبل با بخش اول و بهویژه تکنولوژی DynamIQQ آشنا شدیم و دیدیم که فناوری جدید آرم چگونه با فراهم کردن امکان بهکارگیری هستههای قوی و پرمصرف (big) در کنار هستههای ضعیف و کممصرف (LITTLE) درون یک کلاستر، قرار است جایگزین تکنیک big.LITTLE در سیستمهای روی چیپ (SoC) مبتنی بر معماری آرم شود.
در این قسمت و قسمت آینده، به بررسی تغییرات ریزمعماری هسته میپردازیم.
ریزمعماری Cortex-A75
کورتکس A75 جدیدترین عضو از خانوادهی CPU-های آرم با نام «سوفیا» است که شامل هستههای A12، A17 و A73 میشود. درست مانند هستههای A72 و A57 که هر دو متعلق به خانوادهی آستین بودند و شباهتهای زیادی با یکدیگر داشتند، ریزمعماری A75 نیز بسیار شبیه به A73 است.
آرم در طراحی A73 تمرکز خود را بر بهینگی مصرف انرژی و پایینآوردن دمای پردازنده گذاشته بود؛ درحالیکه در A75، تمرکز اصلی بر افزایش عملکرد هسته و اضافه کردن قابلیتهای جدید بوده است. آرم برای دستیافتن به این هدف تغییرات عمدهای در پایپلاین هسته داده است. استفاده از تکنولوژی DynamIQ نیز برای رسیدن به این هدف چندان بیتأثیر نبوده است. قابلیتهای جدید هسته اما همگی به لطف مهاجرت از معماری ARMv8.0 به ARMv8.22 به وجود آمدهاند.
پیش از ادامه، بد نیست با مفهوم پایپلاین بهصورت مختصر آشنا شویم.
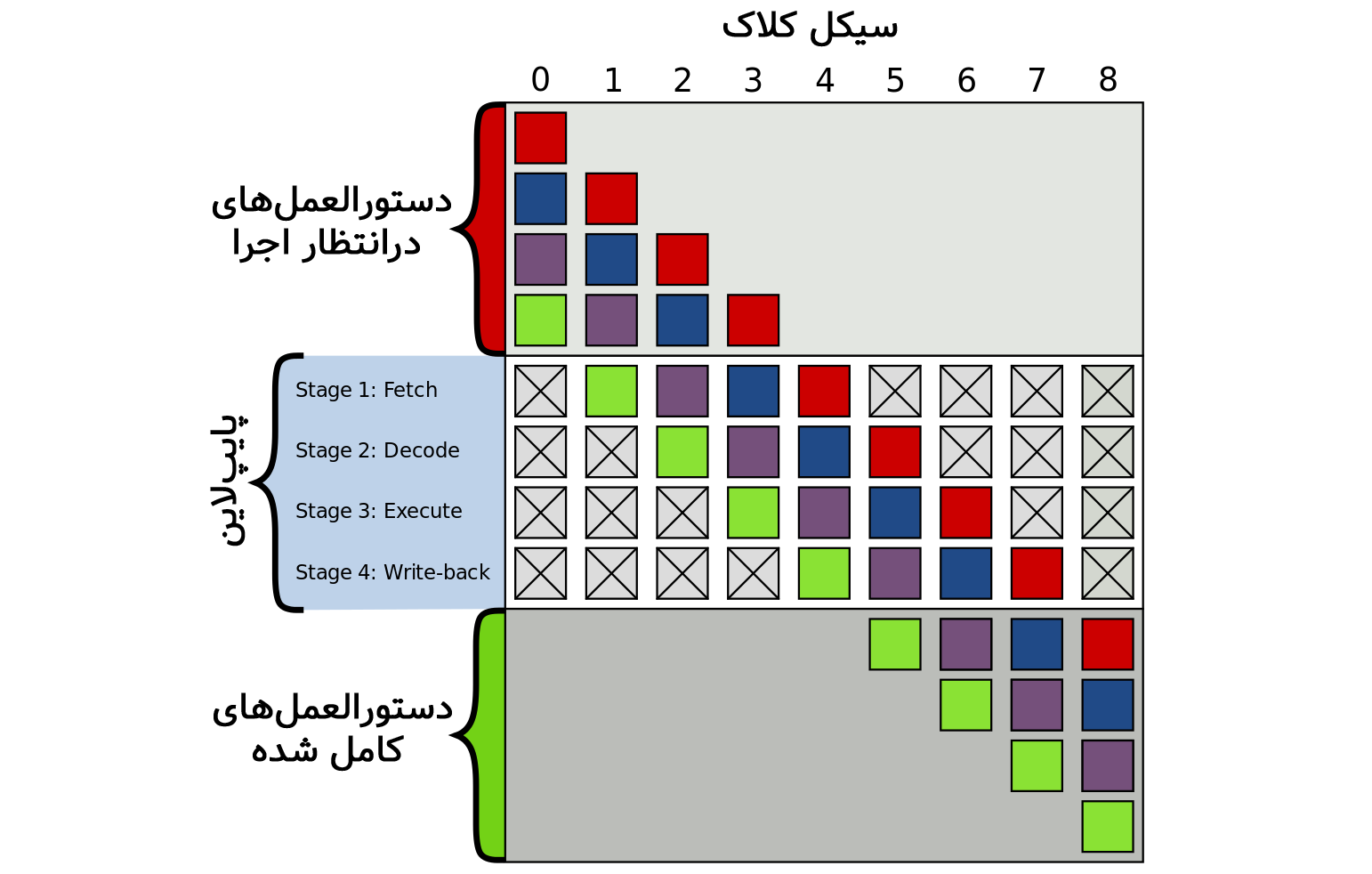
نمونهای از یک پایپلاین ۴ مرحلهای. مربعهای رنگی نشاندهندهی دستورالعملهای مستقل از یکدیگر هستند
«پایپلاین کردن دستورالعمل» (Instruction Pipelining) به تکنیکی گفته میشود که در آن پردازنده مراحل مختلف یک دستورالعمل یا چندین دستورالعمل را بهصورت موازی پردازش میکند. با استفاده از تکنیک پایپلاین، بهجای پردازش هر دستورالعمل در یک سیکل کلاک پردازنده، دستورالعملها در چندمرحله بهصورت همزمان و خارج از نوبت پردازش میشوند. تعداد استیجها یا مراحل پایپلاین به معماری پردازنده بستگی دارد. برای مثال، مراحل پایپلاین کلاسیکRISC از این قرار است:
۱- گرفتن دستورالعمل از حافظه (Fetch)
۲- دیکود کردن دستورالعمل (Decode)
۳- اجرای دستورالعمل (Execute)
۴- دسترسی به مموری (Memory)
۵- بازنویسی نتیجه (Write Back)
A75 از یک پایپلاین نسبتا کوتاه ۱۱ تا ۱۳ مرحلهای مشابه با A73 استفاده میکند. گرفتن دستورالعمل در هستهی جدید هنوز هم ۴ مرحلهای است و دیکودر همچنان قادر است اکثر دستورالعملها را در یک سیکل دیکود کند؛ هرچند دیکود کردن میکرو عملیات (µops) که از مجموعه دستورالعملهای NEON/FP استفاده میکنند، به یک مرحلهی دیگر نیز احتیاج دارد. بزرگترین تفاوت A75 با A73 از لحاظ مراحل پایپلاین، استفاده از دیکود ۳ مرحلهای است که در ادامه دربارهی آن بیشتر توضیح خواهیم داد.
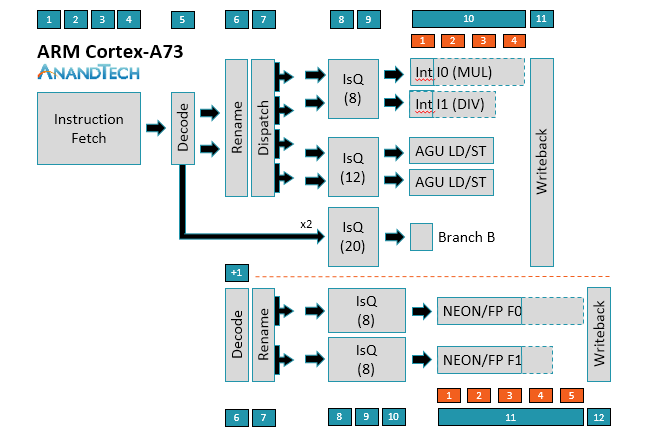
دیاگرام استیجهای پایپلاین هستهی Cortex-A73. قسمت بالا مربوط به محاسبات صحیح و قسمت زیر خطچین، مربوط به محاسبات ممیز شناور است
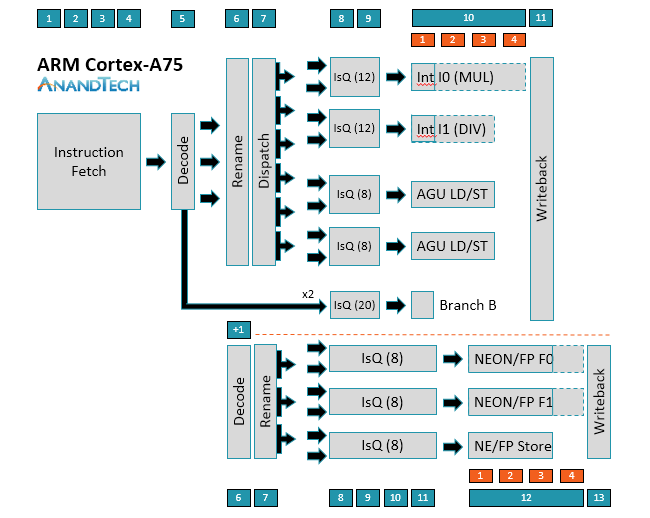
دیاگرام استیجهای پایپلاین هستهی Cortex-A75. قسمت بالا مربوط به محاسبات صحیح و قسمت زیر خطچین، مربوط به محاسبات ممیز شناور است
قابلیت دیکود کردن ۳ دستورالعمل در هر سیکل بهمعنای آن است که A75 میتواند تا ۶ میکرو عملیات را در هر سیکل (µops/cycle) بهانجام برساند. از محاسبات ممیز شناور که بگذریم، به محاسبات صحیح میرسیم. همانطور که از نمودارهای بالا مشخص است، در A75 برخلاف A73 هر ۲ واحد محاسبه و منطق (ALU) و واحد تولید آدرس (AGU)بهجای استفاده از یک صف عملیات بهصورت اشتراکی، صف اختصاصی خود را دارند و A75 میتواند تا ۲ میکرو عملیات را در این صفها قرار بدهد. این موضوع باعث میشود اجرای خارج از نوبت دستورالعملها در A75 بهبود پیدا کند.
همانطور که در دیاگرام مشخص است، میکرو عملیات ساده میتوانند مراحل Rename و Dispatch را دور بزنند و در نتیجه عملا تأخیر ناشی از دو مرحله را حذف کنند. البته دستورالعملهای پیچیده که نیاز به دسترسی رجیسترها دارند، همچنان باید از دو مرحلهی Rename و Dispatch عبور کنند.
اگر دوباره به سمت محاسبات ممیز شناور و دستورالعملهای NEON/FP (قسمت پایینی دو نمودار) بازگردیم، متوجه خواهید شد که مرحلهی Dispatch در این قسمت وجود ندارد. همانطور که مشخص است، میکرو عملیاتها همچنان در صف قرار میگیرند، اما به دلیل حذف مرحلهی Dispatch، این صفها از صفوف قسمت پردازش صحیح دو مرحله زیادتر است.
اگر قسمت محاسبات شناور A75 و A73 را با یکدیگر مقایسه کنیم، متوجه خواهیم شد تعداد صفها به سه عدد افزایش یافته است و دو میکرو عملیات در هر صف میتوانند قرار بگیرند که خود باعث شده است تعداد مراحل مرتبط با صف در A75 به ۴ مرحله افزایش پیدا کند. ARM میگوید هنگام طراحی ریزمعماری A75 افزایش تعداد ورودیهای هر صف را نیز بررسی کرده و در نهایت به این نتیجه رسیده است که افزایش توان مصرفی ناشی از این کار بیشتر از افزایش عملکرد پردازنده است. بههمین دلیل، آرم بهجای اضافه کردن تعداد ورودی به هر صف، تصمیم گرفته است یک پایپ جدید NEON/FP با صف اختصاصی خود ایجاد کند. با این کار میزان تأخیر عملیات ضرب تجمیعی (MAC) نیز از ۶ به ۵۵ سیکل کاهش پیدا کرده است.

A75 همچنان از «ریزمعماری اسلات محور» استفاده میکند که برای اولین بار همراه با A73 معرفی شد. آرم دربارهی این ریزمعماری بهجز اطلاعاتی که سال گذشته منتشر کرد، جزئیات بیشتری ارائه نداده است. تنها در همین حد میدانیم که در این ریزمعماری ۸ «اسلات» وجود دارد که وظیفهی آنها از بین بردن دسترسی بیمورد و غیر ضروری به منابع سیستمی در بلوک دستورالعمل است که در نهایت منجر به کاهش مصرف انرژی میشود.
هم A73 و هم A75 از یک واکشِ اولیهی دستورالعمل استفاده میکنند (Instruction Prefetch یا واکشی اولیهی دستورالعملها، نام تکنیکی است که در آن برای بالارفتن سرعت و پایین آمدن تأخیر، دستورالعملها یا اطلاعات قبل از اینکه حتی به آنها نیاز باشد از رم کشیده و درون کش قرار داده میشوند). این واکشِ اولیه وظیفهی تغذیهی یک کش ۶۴ کیلوبایتی L1 را برعهده دارد.

پیشبینی کنندهی پرش (Branch Predictor) هستهی A75 شاهد بهبود جزئی نسبت به A73 بوده است
آرم در A73 برای اولین بار از یک پیشبینیکنندهی پرش (Branch Predictor، مداری که سعی میکند مسیر یک پرش را قبل از اینکه قطعی شود حدس بزند) جدید برای بالابردن سرعت پیشبینی استفاده کرد. هنگام طراحی A75، آرم متوجه شد که پیشبینیکنندهی پرش A73 همچنان عملکرد رضایتبخشی دارد و افزایش دادن بیش از پیشِ عملکرد آن، ارزش بالا رفتن توان مصرفی پردازنده را ندارد. به همین دلیل در ریزمعماری A75 دقیقا از همان پیشبینیکنندهی پرش A73 استفاده شده است.
همانطور که بالاتر اشاره کردیم، آرم که در A73 از فرآیند دیکود دو مرحلهای استفاده میکرد، تعداد مراحل دیکود را در A75 به سه مرحله افزایش داده است. آرم همواره به دنبال یافتن راهی برای افزایش IPC (دستورالعمل در سیکل) در پردازندههای خود است. درحالیکه پردازندههایی با تراشهی بزرگتر نیز در بنچمارک SPECint 2006 بهزحمت به IPC بالای ۲ میرسند؛ آرم با A73 توانسته بود در این بنچمارک به امتیاز ۱.۲ و در شرایط خاص به ۱.۶ تا ۱.۸ برسد.
البته این به معنای آن نیست که دیکودر ۲ مرحلهای استفاده شده در این هسته کافی بوده است؛ چرا که در شرایط خاصی که به خروجی بیشتر از پردازنده نیاز است، IPC پردازندههای مجهز به A73 به ۰.۶ تا ۰.۴ نیز افت میکرد. بهعنوان مثالی ازشرایط خاص، میتوان به مواقعی اشاره کرد که یک پرش در پیشبینی دچار اشتباه میشود (با احتمال ۲ تا ۴ بار در هر ۱۰۰۰ دستورالعمل) و نیاز است تا CPU صفها را با دستورالعملهای جدید پر کند. البته استفاده از یک صف و مرحلهی اضافه، مصرف هستههای جدید A75 را افزایش میدهد؛ اما این کار برای رسیدن به IPC مورد نظر آرم ضروری بوده است.
مراحل Rename و Dispatch در هستههای جدید درست مانند A73 و دیگر پردازندههای سری سوفیا باقی مانده است و همچنان خبری از بافر بازآرایی (ROB) نیست. در عوض A75 از یک فایل فیزیکی رجیستر برای ذخیرهی میکرو عملیات استفاده میکند که با کاهش انتقال اطلاعات در سطح پردازنده و از بین بردن یک سری باتلنک، باعث میشود مصرف هسته کاهش پیدا کند.
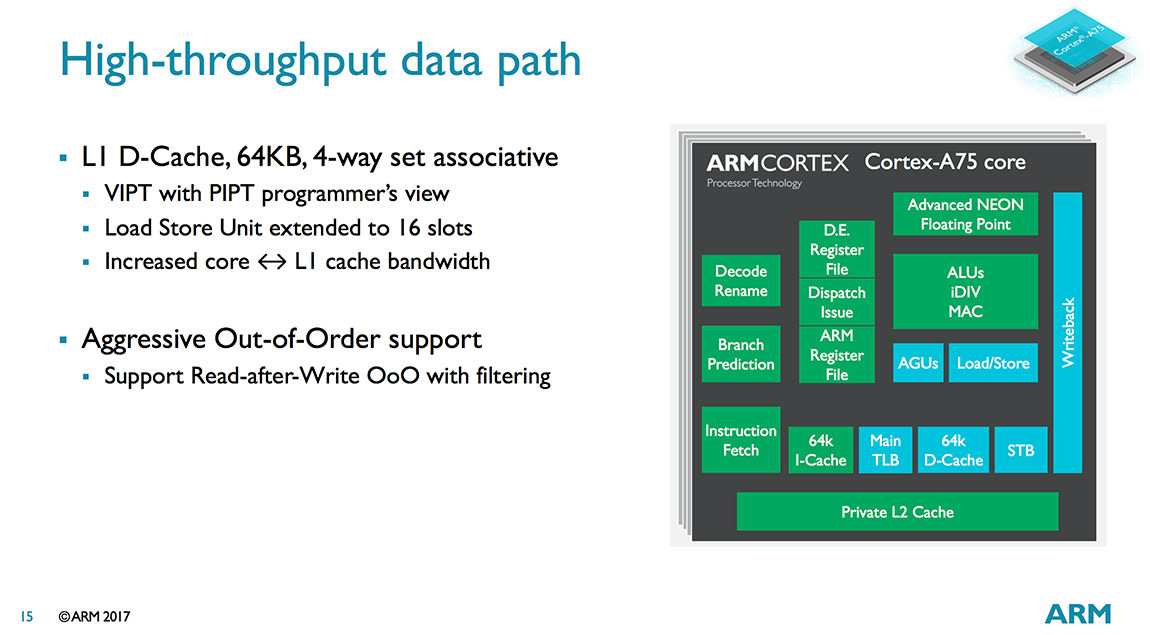
از لحاظ مسیر انتقال اطلاعات، ریزمعماری جدید از یک واکشِ اولیهی بهبودیافته استفاده میکند. اگرچه واکش اولیهی کش L1 و L2 پیش از این در هستههای A73 نیز شاهد اورهال اساسی بوده است، اما آرم برای پردازش بهتر عملیات خارج از نوبت، واکش اولیه را در A75 دوباره مورد بازنگری قرار داده است.
D-کش L1ا ۶۴ کیلوبایتی A73 در A75 نیز تقریبا بدون تغییر باقی مانده است؛ اما تغییر مهم در کش هستهی جدید، استفاده از کش L22 اختصاصی و ادغامشدهای است که با سرعت فرکانس خود هسته کار میکند. کش جدید در مقایسه با کش L2 اشتراکی مورد استفاده توسط هستههای A73، میزان تأخیر را تا ۵۰ درصد کاهش میدهد.
سازندههای SoC میتوانند در هستههای جدید از ۲۵۶ یا ۵۱۲ کیلوبایت کش L2 انتخابی استفاده کنند. استفاده از گزینهی ۵۱۲ کیلوبایتی عملکرد تکهستهی پردازنده را تنها ۲ درصد در مقایسه با کش ۲۵۶ کیلوبایتی افزایش میدهد؛ اما عملکرد چندهستهی پردازنده را (درصورتی که از چهار هستهی A75 و تکنولوژی DynamIQ در آن استفاده شده باشد) تا ۵ درصد افزایش میدهد. نوع بافر تیالبی اصلی در A75 نیز دستخوش تغییر شده است و بافر استور (STB) هم به ۷ اسلات ۱۲۸ بیتی افزایش پیدا کرده است.

در نهایت به پایپلاینهای اجرایی میرسیم. پایپلاینهای ALU/INT درست مانند A73 هستند؛ به این معنی که A75 همچنان نمیتواند دو عمل ضرب یا تقسیم صحیح را بهصورت موازی انجام بدهد. جالب است بدانید آرم پس از مهاجرت به دیکود سه مرحلهای، در نظر داشته است از یک پایپ ALU/INT اضافه نیز استفاده کند، اما پس از انجام آزمایش متوجه شده است میزان بهبود عملکرد ناشی از پایپ جدید، نمیتواند افزایش مصرف هسته را توجیه کند.
دو پایپ ۶۴ بیت NEON/ممیز شناور، مرحلهی Rename و فایل رجیستر ۱۲۸ بیتی اختصاصی خود را دارند که قادر به انجام ۸ عملیات ۸ بیتی صحیح، ۴ عملیات ۱۶ بیتی صحیح، ۲ عملیات ۳۲ بیتی صحیح یا ممیز شناور، یا ۱ عملیات ۶۴ بیتی ممیز شناور دو دقتی در هر سیکل است. این موضوع دست برنامهنویسان را برای در اولویت قرار دادن دقت یاعملکرد در برنامههایشان باز میگذارد.
همچنین به لطف استفاده از معماری ARMv8.2، هستههای A75 بهصورت بومی از عملیات نیم دقتی FP16 پشتیبانی میکنند. استفاده از دادههای کم دقتتر (مانند استفاده از دادههای ۱۶ بیتی در FP16 در مقایسه با دادههای ۳۲ یا ۶۴ بیتی) میزان مموری یا کش مورد نیاز برای ذخیرهی دادهها را کاهش میدهد و باعث افزایش پهنای باند میشود. این معاوضهی دقت با عملکرد، در کاربردهایی مانند یادگیری ماشینی یا پردازش تصویر میتواند بسیار مفید باشد. A73 و دیگر هستههای big نیز پیش از این میتوانستند مقادیر FP16 را از مموری دریافت کنند؛ اما قبل از پردازش مجبور بودند آنها را به FP32 تبدیل کنند که باعث کاهش عملکرد هسته میشد.
در بسیاری از الگوریتمهای شبکههای عصبی پس از اینکه فرآیند آموزش به پایان میرسد، دقت به ۸ بیت کاهش پیدا میکند. برای سرعت دادن به اجرای این نوع الگوریتمها، A75 (یا به بیان دقیقتر معماری ARMv8.2) از مجموعه دستورالعملهای جدید ضرب نقطهای INT8 استفاده میکند که باعث کاهش شدید زمان تأخیر میشود.

در پایان، مهمترین تغییرات هستهی جدید A75 نسبت به نسل قبل را میتوان اینطور خلاصه کرد:
- استفاده از معماری جدید ARMv8.2 (در مقایسه با معماری ARMv8.0 کورتکس A73)
- استفاده از تکنولوژی جدید DynamIQ بهعنوان جایگزینی برای big.LITTLE
- کش L2 اختصاصی و بهبودیافته
- استفاده از کش L3 برای اولین بار
- اضافه شدن یک مرحله و یک پایپ جدید به پایپلاین دستورالعمل
- استفاده از مجموعهی جدید دستورالعملهای NEON برای سرعت دادن به شبکههای عصبی و پردازش تصاویر
در قسمت بعدی به بررسی ریز معماری A55 خواهیم پرداخت.
ادامه دارد...
.: Weblog Themes By Pichak :.
